Création des Logiciels de gestion d'Entreprise, Création et référencement des sites web, Réseaux et Maintenance, Conception

Googlebot activity reports
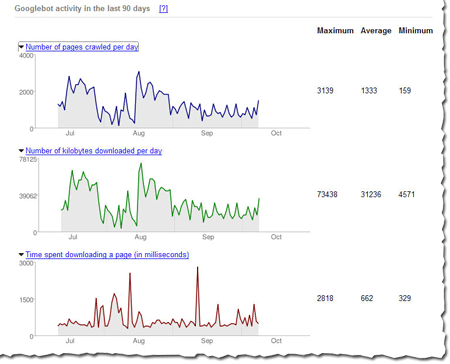
Check out these cool charts! We show you the number of pages Googlebot's crawled from your site per day, the number of kilobytes of data Googlebot's downloaded per day, and the average time it took Googlebot to download pages. Webmaster tools show each of these for the last 90 days. Stay tuned for more information about this data and how you can use it to pinpoint issues with your site.
Crawl rate control
Googlebot uses sophisticated algorithms that determine how much to crawl each site. Our goal is to crawl as many pages from your site as we can on each visit without overwhelming your server's bandwidth.
We've been conducting a limited test of a new feature that enables you to provide us information about how we crawl your site. Today, we're making this tool available to everyone. You can access this tool from the Diagnostic tab. If you'd like Googlebot to slow down the crawl of your site, simply choose the Slower option.
If we feel your server could handle the additional bandwidth, and we can crawl your site more, we'll let you know and offer the option for a faster crawl.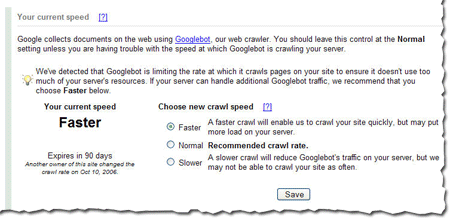
 Number of URLs submitted
Number of URLs submitted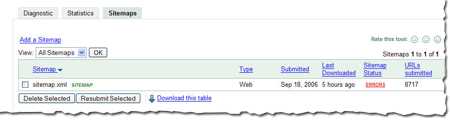 As always, we hope you find these updates useful and look forward to hearing what you think.this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com
As always, we hope you find these updates useful and look forward to hearing what you think.this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.comPeter: It's understandable that webmasters find watermarking images beneficial.Maile: Ahh, I see: Webmasters concerned with search traffic likely want to balance the positives of watermarking with the preferences of their users -- keeping in mind that sites that use clean images without distracting artifacts tend to be more popular, and that this can also impact rankings. Will Google rank an image differently just because it's watermarked?Pros of watermarked imagesIf search traffic is important to a webmaster, then he/she may also want to consider some of our findings:
- Photographers can claim credit/be recognized for their art.
- Unknown usage of the image is deterred.
Findings relevant to watermarked imagesIn summary, if a feature such as watermarking reduces the user-perceived quality of your image or your image's thumbnail, then searchers may select it less often. Preview your images at thumbnail size to get an idea of how the user might perceive it.
- Users prefer large, high-quality images (high-resolution, in-focus).
- Users are more likely to click on quality thumbnails in search results. Quality pictures (again, high-res and in-focus) often look better at thumbnail size.
- Distracting features such as loud watermarks, text over the image, and borders are likely to make the image look cluttered when reduced to thumbnail size.
Peter: Nope. The presence of a watermark doesn't itself cause an image to be ranked higher or lower.


<meta name="GOOGLEBOT" content="NOODP">
Planning on moving your site to a new domain? Lots of webmasters find this a scary process. How do you do it without hurting your site's performance in Google search results?

Let's cover moving your site to a new domain (for instance, changing from www.example.com to www.example.org). This is different from moving to a new IP address; read this post for more information on that.
Here are the main points:
 And as we told you last month, you can see the individual links to pages of your site by going to Links > External links. We hope these details give you additional insight into your site traffic.this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com
And as we told you last month, you can see the individual links to pages of your site by going to Links > External links. We hope these details give you additional insight into your site traffic.this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com


http://www.metrokitchen.com/nice-404-page
"If you're looking for an item that's no longer stocked (as I was), this makes it really easy to find an alternative."-Riona, domestigeek
http://www.comedycentral.com/another-404
"Blame the robot monkeys"-Reid, tells really bad jokes
http://www.splicemusic.com/and-another
"Boost your 'Time on site' metrics with a 404 page like this."-Susan, dabbler in music and Analytics
http://www.treachery.net/wow-more-404s
"It's not reassuring, but it's definitive."-Jonathan, has trained actual spiders to build websites, ants handle the 404s
http://www.apple.com/iPhone4g
"Good with respect to usability."
http://thcnet.net/lost-in-a-forest
"At least there's a mailbox."-JohnMu, adventurous
http://lookitsme.co.uk/404
"It's pretty cute. :)"-Jessica, likes cute things
http://www.orangecoat.com/a-404-page.html
"Flow charts rule."-Sahala, internet traveller
http://icanhascheezburger.com/iz-404-page
"I can has useful links and even e-mail address for questions! But they could have added 'OH NOES! IZ MISSING PAGE! MAYBE TIPO OR BROKN LINKZ?' so folks'd know what's up."-Adam, lindy hop geek

Webmaster level: All
With the number of smartphone users rapidly rising, we’re seeing more and more websites providing content specifically designed to be browsed on smartphones. Today we are happy to announce that Googlebot-Mobile now crawls with a smartphone user-agent in addition to its previous feature phone user-agents. This is to increase our coverage of smartphone content and to provide a better search experience for smartphone users.
Here are the main user-agent strings that Googlebot-Mobile now uses:
Feature phones Googlebot-Mobile:
Smartphone Googlebot-Mobile:
The content crawled by smartphone Googlebot-Mobile will be used primarily to improve the user experience on mobile search. For example, the new crawler may discover content specifically optimized to be browsed on smartphones as well as smartphone-specific redirects.
One new feature we’re also launching that uses these signals is Skip Redirect for Smartphone-Optimized Pages. When we discover a URL in our search results that redirects smartphone users to another URL serving smartphone-optimized content, we change the link target shown in the search results to point directly to the final destination URL. This removes the extra latency the redirect introduces leading to a saving of 0.5-1 seconds on average when visiting landing page for such search results.
Since all Googlebot-Mobile user-agents identify themselves as a specific kind of mobile, please treat each Googlebot-Mobile request as you would a human user with the same phone user-agent. This, and other guidelines are described in our previous blog post and they still apply, except for those referring to smartphones which we are updating today. If your site has treated Googlebot-Mobile specially based on the fact that it only crawls with feature phone user-agents, we strongly recommend reviewing this policy and serving the appropriate content based on the Googlebot-Mobile’s user-agent, so that both your feature phone and smartphone content will be indexed properly.
If you have more questions, please ask on our Webmaster Help forums.
this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com


In the diagram, page-2.html of a series may specify the canonical target as page-all.html because page-all.html is a superset of page-2.html's content. When a user searches for a query term and page-all.html is selected in search results, even if the query most related to page-2.html, we know the user will still see page-2.html’s relevant information within page-all.html.
On the other hand, page-2.html shouldn’t designate page-1.html as the canonical because page-2.html’s content isn’t included on page-1.html. It’s possible that a user’s search query is relevant to content on page-2.html, but if page-2.html’s canonical is set to page-1.html, the user could then select page-1.html in search results and find herself in a position where she has to further navigate to a different page to arrive at the desired information. That’s a poor experience for the user, a suboptimal result from us, and it could also bring poorly targeted traffic to your site.


<head> section:<link rel="next" href="http://www.example.com/article?story=abc&page=2" /><link rel="prev" href="http://www.example.com/article?story=abc&page=1" /><link rel="next" href="http://www.example.com/article?story=abc&page=3" /><link rel="prev" href="http://www.example.com/article?story=abc&page=2" /><link rel="next" href="http://www.example.com/article?story=abc&page=4" /><link rel="prev" href="http://www.example.com/article?story=abc&page=3" /><link> tag). And, if you include a <base> link in your document, relative paths will resolve according to the base URL.<head> section, not within the document <body>.<link rel="canonical" href="http://www.example.com/article?story=abc&page=2”/><link rel="prev" href="http://www.example.com/article?story=abc&page=1&sessionid=123" /><link rel="next" href="http://www.example.com/article?story=abc&page=3&sessionid=123" /><meta name="title" content="Baroo? - cute puppies" />RDFa (Yahoo! SearchMonkey):
<meta name="description" content="The cutest canine head tilts on the Internet!" />
<link rel="image_src" href="http://example.com/thumbnail_preview.jpg" />
<link rel="video_src" href="http://example.com/video_object.swf?id=12345"/>
<meta name="video_height" content="296" />
<meta name="video_width" content="512" />
<meta name="video_type" content="application/x-shockwave-flash" />
<object width="512" height="296" rel="media:video"
resource="http://example.com/video_object.swf?id=12345"
xmlns:media="http://search.yahoo.com/searchmonkey/media/"
xmlns:dc="http://purl.org/dc/terms/">
<param name="movie" value="http://example.com/video_object.swf?id=12345" />
<embed src="http://example.com/video_object.swf?id=12345"
type="application/x-shockwave-flash" width="512" height="296"></embed>
<a rel="media:thumbnail" href="http://example.com/thumbnail_preview.jpg" />
<a rel="dc:license" href="http://example.com/terms_of_service.html" />
<span property="dc:description" content="Cute Overload defines Baroo? as: Dogspeak for 'Whut the...?'
Frequently accompanied by the Canine Tilt and/or wrinkled brow for enhanced effect." />
<span property="media:title" content="Baroo? - cute puppies" />
<span property="media:width" content="512" />
<span property="media:height" content="296" />
<span property="media:type" content="application/x-shockwave-flash" />
<span property="media:region" content="us" />
<span property="media:region" content="uk" />
<span property="media:duration" content="63" />
</object>

item=swedish-fish or category=gummy-candy in the URL http://www.example.com/product.php?item=swedish-fish&category=gummy-candy. {kind=link}