Création des Logiciels de gestion d'Entreprise, Création et référencement des sites web, Réseaux et Maintenance, Conception

<div itemscope itemtype="http://schema.org/VideoObject">
<h2>Video: <span itemprop="name">Title</span></h2>
<meta itemprop="duration" content="T1M33S" />
<meta itemprop="thumbnailUrl" content="thumbnail.jpg" />
<meta itemprop="embedURL"
content="http://www.example.com/videoplayer.swf?video=123" />
<object ...>
<embed type="application/x-shockwave-flash" ...>
</object>
<span itemprop="description">Video description</span>
</div>
User-agent: *Another place to check if a page has been blocked is within the page’s HTML source code itself. You can visit the page and choose “View Page Source” from your browser. Is there a meta noindex tag in the HTML “head” section?
Disallow: /blocked-page/
<html>If they inform you that the page has been removed, you can confirm this by using an HTTP response testing tool like the Live HTTP Headers add-on for the Firefox browser. With this add-on enabled, you can request any URL in Firefox to test that the HTTP response is actually 404 Not Found or 410 Gone.
<head>
<title>blocked page</title>
<meta name="robots" content="noindex">
</head>
...









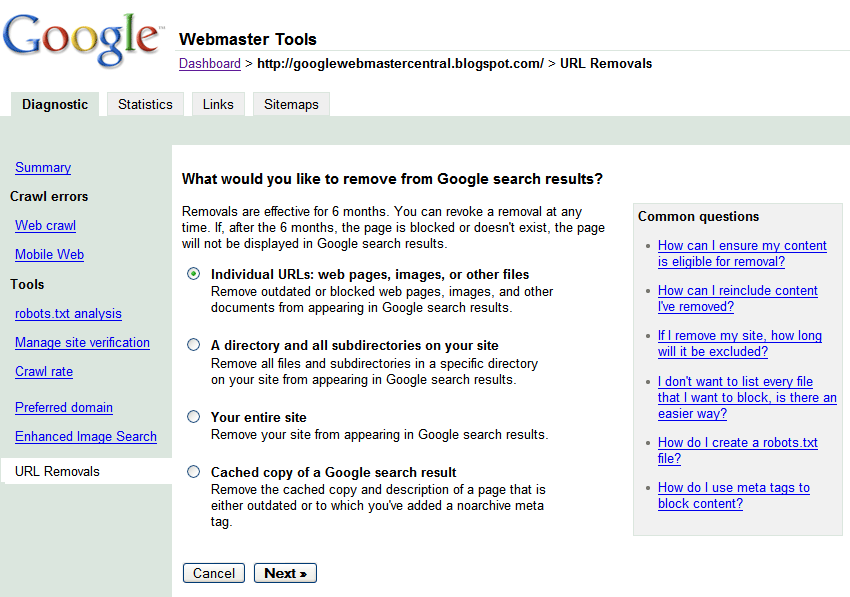
Note: The user-interface of the described features has changed.
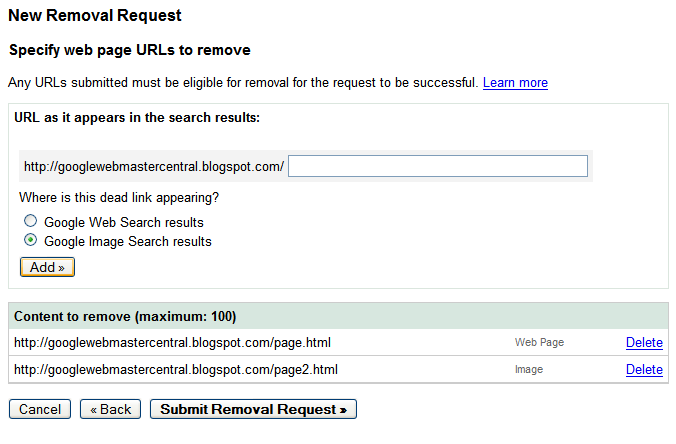 Once the URL is ready for removal, enter the URL and indicate whether it appears in our web search results or image search results. Then click Add. You can add up to 100 URLs in a single request. Once you've added all the URLs you would like removed, click Submit Removal Request.
Once the URL is ready for removal, enter the URL and indicate whether it appears in our web search results or image search results. Then click Add. You can add up to 100 URLs in a single request. Once you've added all the URLs you would like removed, click Submit Removal Request.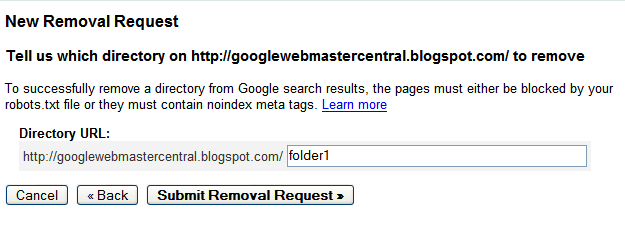 Your entire site
Your entire site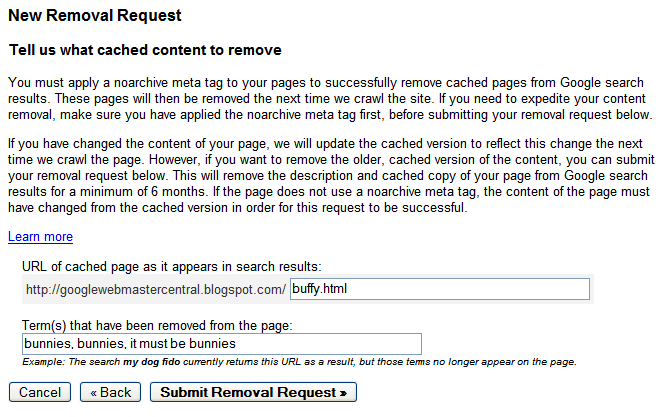 Checking the status of removal requests
Checking the status of removal requests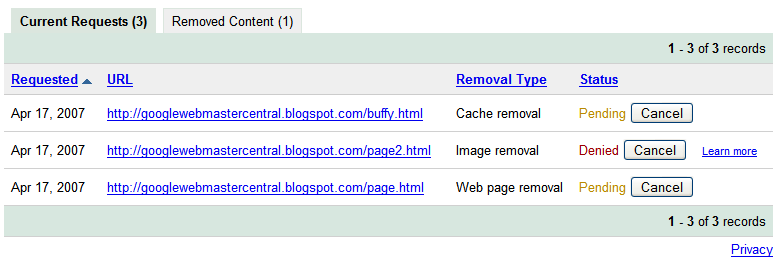
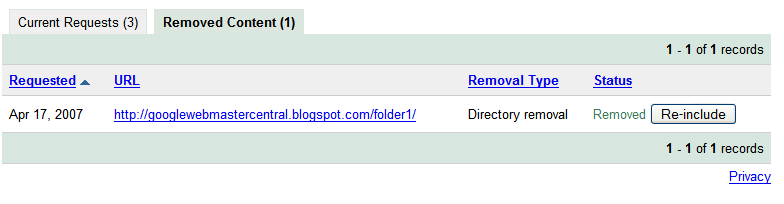 Requesting removal of content you don't own
Requesting removal of content you don't own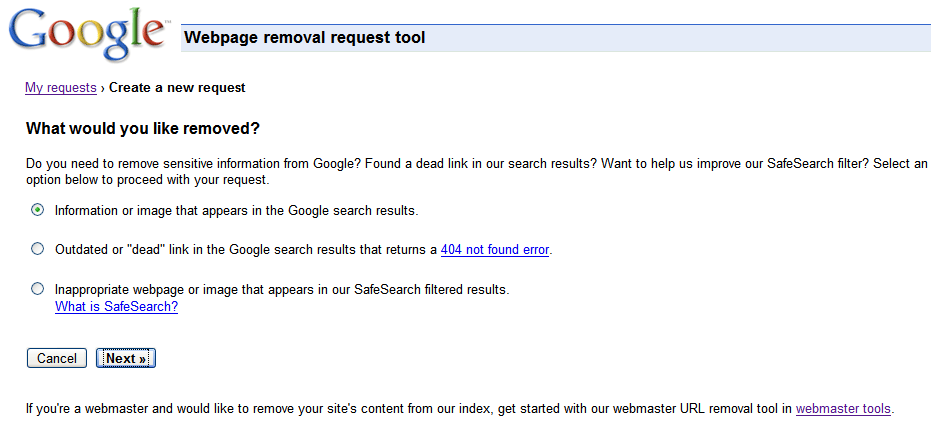 Since Google indexes the web and doesn't control the content on web pages, we generally can't remove results from our index unless the webmaster has blocked or modified the content or removed the page. If you would like content removed, you can work with the site owner to do so, and then use this tool to expedite the removal from our search results.
Since Google indexes the web and doesn't control the content on web pages, we generally can't remove results from our index unless the webmaster has blocked or modified the content or removed the page. If you would like content removed, you can work with the site owner to do so, and then use this tool to expedite the removal from our search results.
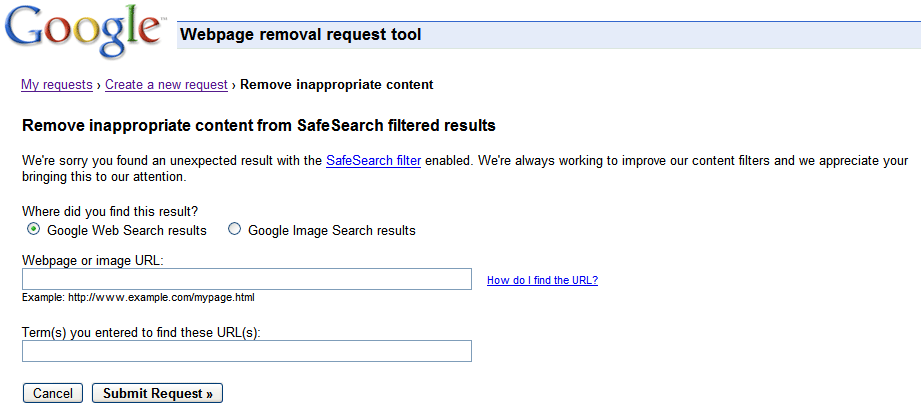 You can check on the status of pending requests, and as with the version available in webmaster tools, the status will change to Removed or Denied once it's been processed. Generally, the request is denied if it doesn't meet the eligibility criteria. For requests that involve personal information, you won't see the status available here, but will instead receive an email with more information about next steps.
You can check on the status of pending requests, and as with the version available in webmaster tools, the status will change to Removed or Denied once it's been processed. Generally, the request is denied if it doesn't meet the eligibility criteria. For requests that involve personal information, you won't see the status available here, but will instead receive an email with more information about next steps.Peter: It's understandable that webmasters find watermarking images beneficial.Maile: Ahh, I see: Webmasters concerned with search traffic likely want to balance the positives of watermarking with the preferences of their users -- keeping in mind that sites that use clean images without distracting artifacts tend to be more popular, and that this can also impact rankings. Will Google rank an image differently just because it's watermarked?Pros of watermarked imagesIf search traffic is important to a webmaster, then he/she may also want to consider some of our findings:
- Photographers can claim credit/be recognized for their art.
- Unknown usage of the image is deterred.
Findings relevant to watermarked imagesIn summary, if a feature such as watermarking reduces the user-perceived quality of your image or your image's thumbnail, then searchers may select it less often. Preview your images at thumbnail size to get an idea of how the user might perceive it.
- Users prefer large, high-quality images (high-resolution, in-focus).
- Users are more likely to click on quality thumbnails in search results. Quality pictures (again, high-res and in-focus) often look better at thumbnail size.
- Distracting features such as loud watermarks, text over the image, and borders are likely to make the image look cluttered when reduced to thumbnail size.
Peter: Nope. The presence of a watermark doesn't itself cause an image to be ranked higher or lower.


