The true North South divide
Just lately we have started to read in the UK newspapers that property prices are set to tumble. Living in the so-called affluent South in a small coastal town I long for the day that house prices do exactly that.
My home is a 3 bed roomed terraced house. It's no better nor worse than most other average family homes up and down the length and breadth of the UK, but there is one crucial difference. That is its value. Here in the South-East property prices are dizzyingly expensive. My little house would fetch around £270,000 if I were ever to sell it. To make the move to a more expensive home worth anything up to £500,000, I would be required to pay 3% of the new property's purchase price in Stamp Duty Land Tax. For properties priced between £500,001 and £1,000,000, the tax increases to 4%, and if I were to leap up the ladder to a house valued at more than a million my payment to the treasury would be 5% of it's sale price. Here in the South-East we are obliged to pay through the nose for quite average homes, and then pay taxes on top for the privilege. Elsewhere in the UK property prices are no-where near as prohibitive, and consequently there are huge numbers of home owners living in Britain who will never pay a penny to the government in Stamp Duty. For properties priced between £125,001 and £250,000 the duty is levied at a mere 1%. Beneath that price the duty disappears altogether.
For ordinary, working families living in the South-East of England, property ownership comes at a very high price indeed, and government policies in this instance, do little to alleviate the financial pain. The Chancellor of the Exchequor, Geaorge Osborne, missed an opportunity to remedy this in his 2013 spring budget. Instead he opted to channel resources into maintaining the status quo, and the government will implement a series of measures to help people raise the enormous deposits required by the banks to put down on over-priced homes.
However, for those whose jobs are more mobile, there is a whole wealth of property readily available in cheaper areas of the UK. Here are some places you might wish to consider in your search for an affordable three-bed roomed house. All prices given were found on the Right move web-site, and are current for February 2013.
1. Rhondda, Glamorgan
In the Rhondda Valley area of beautiful Wales, a three bed roomed terraced home can be purchased for as little as £35,000. My search also revealed one house in need of updating in Treorchy for just £25,000, but there were a number of others, all advertised as being in good order, in the £35,000 to £40,000 price range. Some of the locations listed in this price bracket are Cwmparc, Treorchy and Tynewydd. This area has shown a rise in prices over the two years since I first complied this list, but still represents exceptional value compared to other parts of the UK.
The Rhondda Valley is most notable for its historical link to the coal mining industry, and the closure of many local pits in the 1990s left a legacy of high unemployment. The vast amount of low-priced homes for sale in this region is a reflection of the pain that these communities continue to feel.
2. Liverpool
Once, famously, home to the Beatles and Cilla Black, lively Liverpool with all it's musical and artistic heritage, has a plentiful supply of reasonably priced three bedroomed terraced houses. The lowest priced example I came across in this area was a home in nearby Bootle which is being offered at £34,500, and there are a number of attractive, basic properties available in the Liverpool area in the £35,000 to £40,000 price bracket. Shared ownership schemes seem to be popular in this region, and many, reasonably priced, brand new homes, come to the market offering 25% to 75% shared ownership.
In recent years, Liverpool has been transformed into one of the UK’s leading business destinations by an ambitious and far-reaching regeneration programme. Although the plethora of cheap housing seems to tell it's own story, it may just be that the house prices are only temporarily lagging behind the bigger picture. Certainly, here, as in other areas I've investigated, there has been a significant rise in house prices at the lower end of the scale.
3. Stoke-on-Trent
Stoke-on-Trent is well known for the numerous potteries that grew up in and around the town from the 17th century onwards. Wedgwood, Minton and Royal Doulton are among the more famous china manufacturers from this area, and the potteries, together with abundant local supplies of coal and iron, ensured the prosperity of the region for several centuries. More recently, however, with pit closures, and the loss of numerous factories and steelworks, there has been a sharp rise in unemployment. Nowadays, local tourism opportunities are beginning to be exploited, and both the china works, and the canal system draw their fair share of visitors to the region each year.
A three-bedroomed, terraced house in the Potteries area can be bought for as little as £40,000 to £45,000. A semi-detached home, in good order, sells for as little as £55,000.
4. Wakefield, West Yorkshire
The site of a battle during the Wars of the Roses, Wakefield developed over the centuries, into an important market town and centre for wool, exploiting its position on the navigable River Calder to become an inland port. In more recent years, Wakefield has seen a decline in it's fortunes as the textiles and glass making factories which first made it wealthy finally closed in the 1970s and 1980s. This was further compounded by pit closures, which resulted in high levels of unemployment.
In Castleford, Hunslet and Royston, three bedroomed homes are readily available in the £45,000 to £55,000 price bracket. The lower end prices are a little higher in nearby Wakefield, Pontefract, Leeds and Barnsley, but all show listings for comfortable, habitable properties around £65,000.
5. Newcastle-upon-Tyne
Three bedroomed houses priced at between £55,000 and £65,000 are plentiful in the Newcastle upon-Tyne area of Tyne & Wear. The port developed in the 16th century and, along with the shipyards lower down the river Tyne, it became one of the world's largest ship-building and ship-repairing centres. These industries have since gone into decline, and today, Newcastle-upon-Tyne is largely a business and cultural centre, with a lively nightlife. Newcastle-upon Tyne has shown one of the largest increases in property prices since this list was first compiled in 2011, and the prices appear to be rising much faster than the national average.
6. Belfast and Antrim
Famous for being home to the shipyard that built the Titanic, the hilly streets of beautiful Belfast have seen more than their fair share of problems over the years. The continuing sectarian conflict that has divided communities in this city, is in sharp contrast, however, to the warm welcome that visitors receive here. Belfast has a vibrant and thriving city centre with great leisure facilities, historic sites to visit, fabulous shopping streets and excellent transport links. A comfortable three-bedroomed home in nearby Antrim or Newtownabbey could be yours from as little as 70,000, but you'll have to be quick, as the available housing stocks as at February 2013, are very, very low.
7. Hull
Historic Kingston-Upon-Hull, better known as just plain 'Hull' has poetic and theatrical links as well as a fascinating maritime past. Recent investment in urban regeneration has brought about much improvement in poorer areas in and around the city, but the property prices remain some of the UK's lowest. I found a number of three-bedroomed terraced houses advertised for sale priced at around £49,950, all within a ten mile radius of Hull City Centre. Homes in the £55,000 to £65,000 price range are readily available. If you have a little more to spend, £249,500 will buy you a spacious, detached house with good sized gardens, in one of the better areas. and you could still avoid the Chancellor's 3% stamp duty bracket.
8. Sheffield, South Yorkshire
Industrious Sheffield, famous for it's cutlers and surrounded by some of Britain's most ruggedly beautiful countryside, this city has seen tough times in more recent years. Like many of the areas listed here, Sheffield has seen employment prospects wax and wane, but it still remains a vibrant University City with many galleries and museums to browse, and great sporting and leisure facilities. Three-bedroomed terraced houses can be bought for as little as £50,000, and there are a number available in the £55,000 to £65,000 price bracket both in Sheffield, and in the surrounding towns and villages.
9.Birmingham
Birmingham, in the West Midlands county of England, is the UK's second most populous city after London. Once at the forefront of the industrial revolution, Birmingham remains a major international commercial centre. It is home to no less than three universities, and is also the site of Britain's National Exhibition Centre. Despite it's sprawling, urban environment, Birmingham enjoys over 8,000 acres of parkland within it's boundaries and also has a fascinating and picturesque network of canals and waterways running through the city.
Three bedroomed houses in the Birmingham districts of Smethwick and Oldbury begin at between £65,000 and £75,000
10. Swansea, South Wales
Swansea and Port Talbot can trace their roots back to the stone age. The Romans and the Vikings both came and put their mark on these ancient settlements, and the people of these towns have been seafarers, ship-builders, merchants, and coal-miners. Situated on the edge of the beautiful Gower Peninsula, this part of Wales has much to recommend it, not least it's property prices. The lowest priced 3 bedroom terraced homes can be bought for as little as £55,000. 


















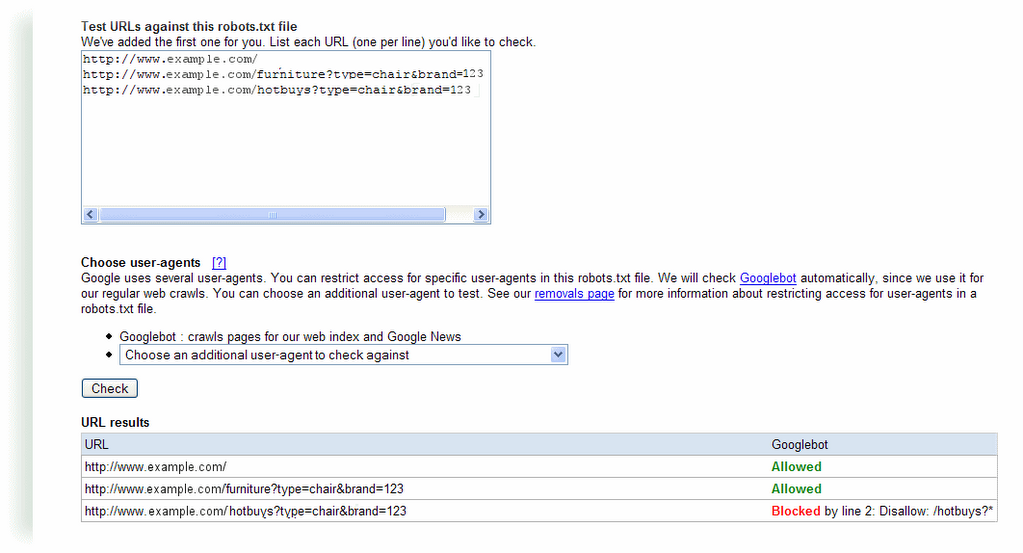 Don't worry about links to anchors, because while Googlebot will crawl each link, our algorithms will index the URL without the anchor.
Don't worry about links to anchors, because while Googlebot will crawl each link, our algorithms will index the URL without the anchor.

 One of the best things about attending Google I/O is the chance to meet developers who are using our APIs and interacting with Google technology in ways we could never imagine. Not only was it amazing to see exciting examples of apps built on the AJAX and Data APIs being demoed at the developer sandbox, but it was also interesting to meet other developers who are just starting to use many of our APIs for their specific needs and cool ideas. Hopefully, by making all of our sessions available for free to watch on your own time, many of you who are interested in Google's APIs will get a better understanding of the ways we are making our API offerings easier to use, more efficient and much more feature rich.
One of the best things about attending Google I/O is the chance to meet developers who are using our APIs and interacting with Google technology in ways we could never imagine. Not only was it amazing to see exciting examples of apps built on the AJAX and Data APIs being demoed at the developer sandbox, but it was also interesting to meet other developers who are just starting to use many of our APIs for their specific needs and cool ideas. Hopefully, by making all of our sessions available for free to watch on your own time, many of you who are interested in Google's APIs will get a better understanding of the ways we are making our API offerings easier to use, more efficient and much more feature rich.