Création des Logiciels de gestion d'Entreprise, Création et référencement des sites web, Réseaux et Maintenance, Conception

Update: The described feature is no longer available.
Make sure your content is viewable
Be descriptive
Keep the site crawlable
Our search quality and Webmaster Central teams love helping webmasters solve problems. But since we can't be in all places at all times answering all questions, we also try hard to show you how to help yourself. We put a lot of work into providing documentation and blog posts to answer your questions and guide you through the data and tools we provide, and we're constantly looking for ways to improve the visibility of that information.
While I always encourage people to search our Help Center and blog for answers, there are a few articles in particular to which I'm constantly referring people. Some are recent and some are buried in years' worth of archives, but each is worth a read:
Sometimes, knowing how to find existing information is the biggest barrier to getting a question answered. So try searching our blog, Help Center and Help Group next time you have a question, and please let us know if you can't find a piece of information that you think should be there!
this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com

 |
| Example of a Site Error alert |
 |
| Example of a URL Error anomaly alert |
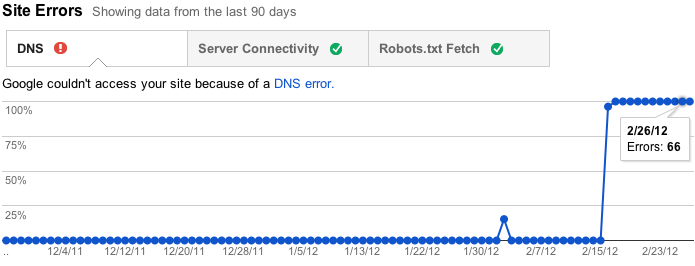 |
| View site error rate and counts over time |
 |
| A site with no recent site-level errors |
 |
| URL errors by type with full current and historical counts |
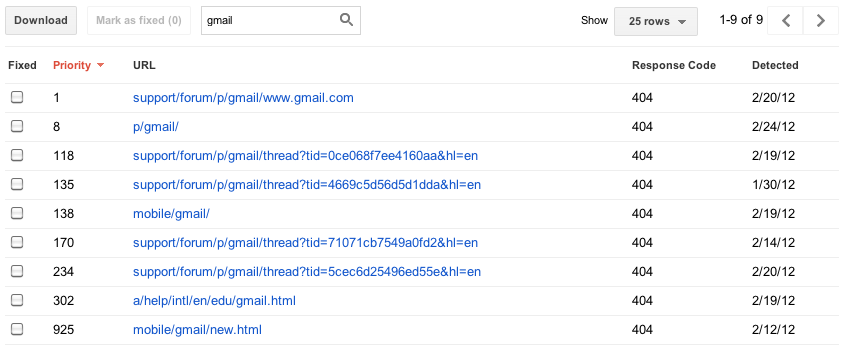 |
| Instantly filter and sort errors on any column |
 |
| Details for each URL error |
 |
| View pages which link to this URL |
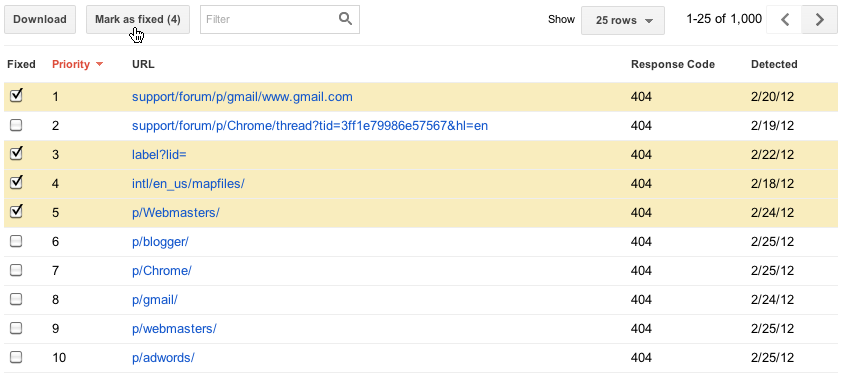 |
| Select errors and mark them as fixed |





Note: The SEO Starter Guide has since been updated.




 |
| Bryan |
 |
| Libo |
A year ago, we released a preview of the PageSpeed Insights Chrome Developer Tools extension, which analyzes the performance of web pages and provides suggestions to make them faster. Today, we’re releasing version 2.0 of the PageSpeed Insights extension, available in the Chrome Web Store. PageSpeed Insights analyzes all aspects of a web page load and points out the specific things you can do to make your page faster. For instance, PageSpeed Insights can inform you about an expensive JavaScript call that blocks the renderer for too long, remind you about that new photo on the front page of your web site that you might have forgotten to resize or optimize, or recommend changing the way you load third-party content so it no longer blocks the page load.
PageSpeed Insights for Chrome is a Developer Tools extension that analyzes all aspects of the page load, including resources, network, DOM, and the timeline. If you're already familiar with the Developer Tools, you'll find that PageSpeed Insights integrates with a toolset you're already using.

Using technologies like Native Client, PageSpeed Insights is able to run the open-source PageSpeed Insights SDK securely and with the performance of native code. Leveraging the Insights SDK enables the Chrome extension to automatically optimize the images, CSS, JavaScript and HTML resources on your web page and provide versions of those resources that you can easily deploy on your website.
We hope you’ll give PageSpeed Insights for Chrome a try and start optimizing your web pages today. We’d love to hear from you, as always. Please try PageSpeed Insights for Chrome, and give us feedback on our mailing list with questions, comments, and new features you’d like to see.

Update 19 February 2013: Data Highlighter for events structured markup is available in all languages in Webmaster Tools.
At Google we're making more and more use of structured data to provide enhanced search results, such as rich snippets and event calendars, that help users find your content. Until now, marking up your site's HTML code has been the only way to indicate structured data to Google. However, we recognize that markup may be hard for some websites to deploy.
Today, we're offering webmasters a simpler alternative: Data Highlighter. At initial launch, it's available in English only and for structured data about events, such as concerts, sporting events, exhibitions, shows, and festivals. We'll make Data Highlighter available for more languages and data types in the months ahead. Update 19 February 2013: Data Highlighter for events structured markup is available in all languages in Webmaster Tools.
Data Highlighter is a point-and-click tool that can be used by anyone authorized for your site in Google Webmaster Tools. No changes to HTML code are required. Instead, you just use your mouse to highlight and "tag" each key piece of data on a typical event page of your website:
If your page lists multiple events in a consistent format, Data Highlighter will "learn" that format as you apply tags, and help speed your work by automatically suggesting additional tags. Likewise, if you have many pages of events in a consistent format, Data Highlighter will walk you through a process of tagging a few example pages so it can learn about their format variations. Usually, 5 or 10 manually tagged pages are enough for our sophisticated machine-learning algorithms to understand the other, similar pages on your site.
When you're done, you can review a sample of all the event data that Data Highlighter now understands. If it's correct, click "Publish."
From then on, as Google crawls your site, it will recognize your latest event listings and make them eligible for enhanced search results. You can inspect the crawled data on the Structured Data Dashboard, and unpublish at any time if you're not happy with the results.
Here’s a short video explaining how the process works:
To get started with Data Highlighter, visit Webmaster Tools, select your site, click the "Optimization" link in the left sidebar, and click "Data Highlighter".
If you have any questions, please read our Help Center article or ask us in the Webmaster Help Forum. Happy Highlighting!
this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com











{kind=link}