Création des Logiciels de gestion d'Entreprise, Création et référencement des sites web, Réseaux et Maintenance, Conception



| Parameter name | Effect on content? | What should Googlebot crawl? |
|---|---|---|
| trackingId | None | One representative URL |
| sortOrder | Sorts | Only URLs with value = ‘lowToHigh’ |
| sortBy | Sorts | Only URLs with value = ‘price’ |
| filterByColor | Narrows | No URLs |
| itemId | Specifies | Every URL |
| page | Paginates | Every URL |
Webmaster level: Intermediate
We’ve noticed a rise in the number of questions from webmasters about how best to structure a website for mobile phones and how websites can best interact with Googlebot-Mobile. In this post we’ll explain the current situation and give you specific recommendations you can implement now.
Let’s start with a simple question: what do we mean by “mobile phone” when talking about mobile-friendly websites?
A good way to answer this question is to think about the capabilities of the mobile phone’s web browser, especially in relation to the capabilities of modern desktop browsers. To simplify matters, we can break mobile phones into a few classifications:
We can further break down this category by support for HTML5:
Once upon a time, mobile phones connected to the Internet using browsers with limited rendering capabilities; but this is clearly a changing situation with the fast rise of smartphones which have browsers that rival the full desktop experience. As such, it’s important to note that the distinction we are making here is based on the current situation as we see it and might change in the future.
Google has two crawlers relevant to this topic: Googlebot and Googlebot-Mobile. Googlebot crawls desktop-browser type of webpages and content embedded in them and Googlebot-Mobile crawls mobile content. The questions we’re seeing more of can be summed up as follows:
Given the diversity of capabilities of mobile web browsers, what kind of content should I serve to Googlebot-Mobile?
The answer lies in the User-agent that Googlebot-Mobile supplies when crawling. There are several User-agent strings in use by Googlebot-Mobile, all of which use this format:
[Phone name(s)] (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
To decide which content to serve, assess which content your website has that best serves the phone(s) in the User-agent string. A full list of Googlebot-Mobile User-agents can be found here.
Notice that we currently do not crawl with Googlebot-Mobile using a smartphone User-agent string. Thus at the current time, a correctly-configured content serving system will serve Googlebot-Mobile content only for the traditional phones described above, because that’s what the User-agent strings in use today dictate. This may change in the future, and if so, it may mean there would be a new Googlebot-Mobile User-agent string.
For now, we expect smartphones to handle desktop experience content so there is no real need for mobile-specific effort from webmasters. However, for many websites it may still make sense for the content to be formatted differently for smartphones, and the decision to do so should be based on how you can best serve your users.
The next set of questions ask about the URLs mobile content should be served from. Let’s look in detail at some common use cases.
Most websites currently have only one version of their content, namely in HTML that is designed for desktop web browsers. This means all browsers access the content from the same URL.
These websites may not be serving traditional mobile phone users. The quality experienced by their smartphone users depends on the mobile browser they are using and it could be as good as browsing from the desktop.
If you serve only desktop experience content for all User Agents, you should do so for Googlebot-Mobile too; that is, treat Googlebot-Mobile as you treat all other or unknown User Agents. In these cases, Google may modify your webpages for an improved mobile experience.
Many websites have content specifically optimized for mobile users. The content could be simply reformatted for the typically smaller mobile displays, or it could be in a different format (e.g., served using WAP, etc.).
A very common question we see is: Does it matter if the different types of content are served from the same URL or from different URLs? For example, some websites have www.example.com as the URL desktop browsers are meant to access and have m.example.com or wap.example.com for the different mobile devices. Other websites serve all types of content from just one URL structure like www.example.com.
For Googlebot and Googlebot-Mobile, it does not matter what the URL structure is as long as it returns exactly what a user sees too. For example, if you redirect mobile users from www.example.com to m.example.com, that will be recognized by Googlebot-Mobile and both websites will be crawled and added to the correct index. In this case, use a 301 redirect for both users and Googlebot-Mobile.
If you serve all types of content from www.example.com, i.e. serving desktop-optimized content or mobile-optimized content from the same URL depending on the User-agent, this will also lead to correct crawling by Googlebot and Googlebot-Mobile. This is not considered cloaking by Google.
It is worth repeating that regardless of URL structure, you must correctly detect the User-agent as given by your users and Googlebot-Mobile, and serve both the same content. Don’t forget to keep the default content, the desktop-optimized content, for when an unknown User-agent requests it.
Finally, we receive many questions about what URLs to put in Mobile Sitemaps. As explained in our Mobile Sitemaps Help Center articles, you should include only mobile content URLs in Mobile Sitemaps, even if these URLs also return non-mobile content when accessed by a non-mobile User-agent.
A good place to start is our Mobile Sites Help Center articles and the relevant sections in our Search Engine Optimization Starter Guide. We also created a thread in our forums for you to ask questions about this post.
this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com
 |
| SES Chicago: Googlers Trevor Foucher, Adam Lasnik and Jonathan Simon |
<div itemscope itemtype="http://schema.org/VideoObject">
<h2>Video: <span itemprop="name">Title</span></h2>
<meta itemprop="duration" content="T1M33S" />
<meta itemprop="thumbnailUrl" content="thumbnail.jpg" />
<meta itemprop="embedURL"
content="http://www.example.com/videoplayer.swf?video=123" />
<object ...>
<embed type="application/x-shockwave-flash" ...>
</object>
<span itemprop="description">Video description</span>
</div>
Telling webmasters to use DNS to verify on a case-by-case basis seems like the best way to go. I think the recommended technique would be to do a reverse DNS lookup, verify that the name is in the googlebot.com domain, and then do a corresponding forward DNS->IP lookup using that googlebot.com name; eg:
> host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
> host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
I don't think just doing a reverse DNS lookup is sufficient, because a spoofer could set up reverse DNS to point to crawl-a-b-c-d.googlebot.com.

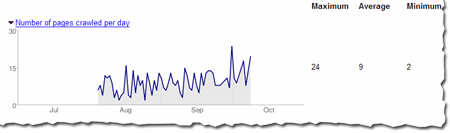

 In general, the load time of a page doesn't affect its ranking, but we wanted to give this info because it can help you spot problems. We hope you will find this data as useful as we do!this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com
In general, the load time of a page doesn't affect its ranking, but we wanted to give this info because it can help you spot problems. We hope you will find this data as useful as we do!this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.comUser-agent: *Googlebot will crawl everything in the site other than pages in the cgi-bin directory.
Disallow: /
User-agent: Googlebot
Disallow: /cgi-bin/
User-agent: *Googlebot won't crawl any pages of the site.
Disallow: /

When a mobile user or crawler (like Googlebot-Mobile) accesses the desktop version of a URL, you can redirect them to the corresponding mobile version of the same page. Google notices the relationship between the two versions of the URL and displays the standard version for searches from desktops and the mobile version for mobile searches.
If you redirect users, please make sure that the content on the corresponding mobile/desktop URL matches as closely as possible. For example, if you run a shopping site and there's an access from a mobile phone to a desktop-version URL, make sure that the user is redirected to the mobile version of the page for the same product, and not to the homepage of the mobile version of the site. We occasionally find sites using this kind of redirect in an attempt to boost their search rankings, but this practice only results in a negative user experience, and so should be avoided at all costs.
On the other hand, when there's an access to a mobile-version URL from a desktop browser or by our web crawler, Googlebot, it's not necessary to redirect them to the desktop-version. For instance, Google doesn't automatically redirect desktop users from their mobile site to their desktop site, instead they include a link on the mobile-version page to the desktop version. These links are especially helpful when a mobile site doesn't provide the full functionality of the desktop version -- users can easily navigate to the desktop-version if they prefer.
Some sites have the same URL for both desktop and mobile content, but change their format according to User-agent. In other words, both mobile users and desktop users access the same URL (i.e. no redirects), but the content/format changes slightly according to the User-agent. In this case, the same URL will appear for both mobile search and desktop search, and desktop users can see a desktop version of the content while mobile users can see a mobile version of the content.
However, note that if you fail to configure your site correctly, your site could be considered to be cloaking, which can lead to your site disappearing from our search results. Cloaking refers to an attempt to boost search result rankings by serving different content to Googlebot than to regular users. This causes problems such as less relevant results (pages appear in search results even though their content is actually unrelated to what users see/want), so we take cloaking very seriously.
So what does "the page that the user sees" mean if you provide both versions with a URL? As I mentioned in the previous post, Google uses "Googlebot" for web search and "Googlebot-Mobile" for mobile search. To remain within our guidelines, you should serve the same content to Googlebot as a typical desktop user would see, and the same content to Googlebot-Mobile as you would to the browser on a typical mobile device. It's fine if the contents for Googlebot are different from the one for Googlebot-Mobile.
One example of how you could be unintentionally detected for cloaking is if your site returns a message like "Please access from mobile phones" to desktop browsers, but then returns a full mobile version to both crawlers (so Googlebot receives the mobile version). In this case, the page which web search users see (e.g. "Please access from mobile phones") is different from the page which Googlebot crawls (e.g. "Welcome to my site"). Again, we detect cloaking because we want to serve users the same relevant content that Googlebot or Googlebot-Mobile crawled.

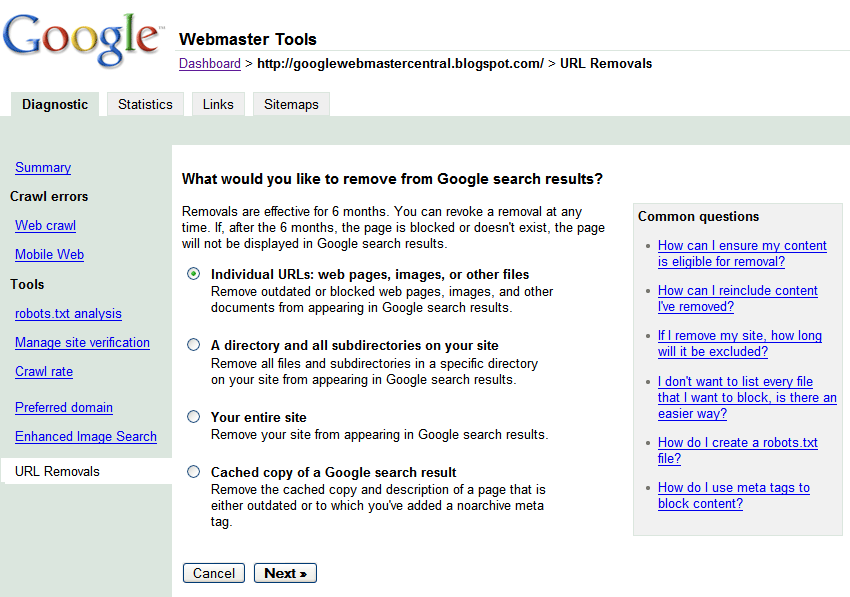
Note: The user-interface of the described features has changed.
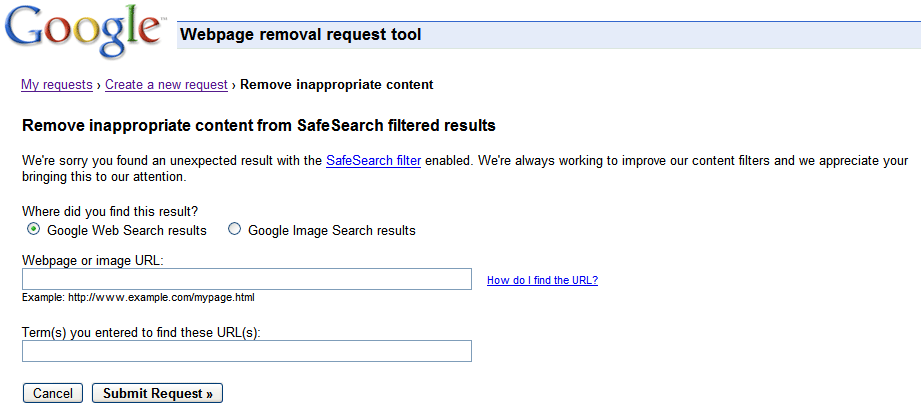
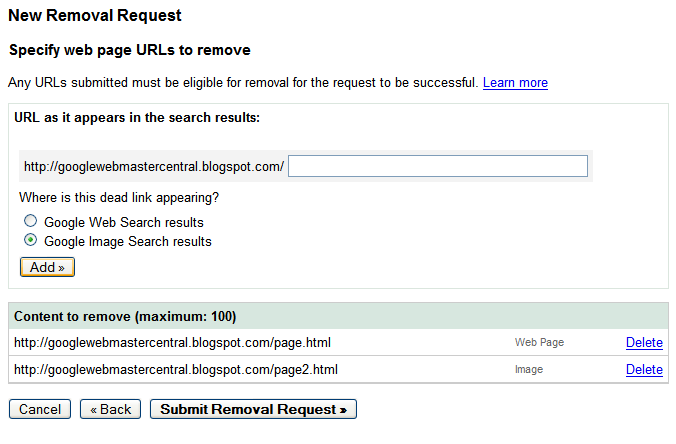 Once the URL is ready for removal, enter the URL and indicate whether it appears in our web search results or image search results. Then click Add. You can add up to 100 URLs in a single request. Once you've added all the URLs you would like removed, click Submit Removal Request.
Once the URL is ready for removal, enter the URL and indicate whether it appears in our web search results or image search results. Then click Add. You can add up to 100 URLs in a single request. Once you've added all the URLs you would like removed, click Submit Removal Request.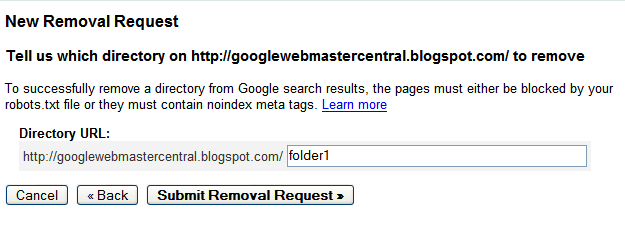 Your entire site
Your entire site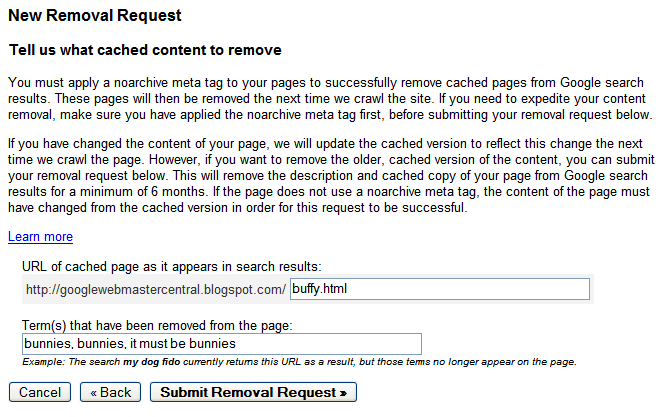 Checking the status of removal requests
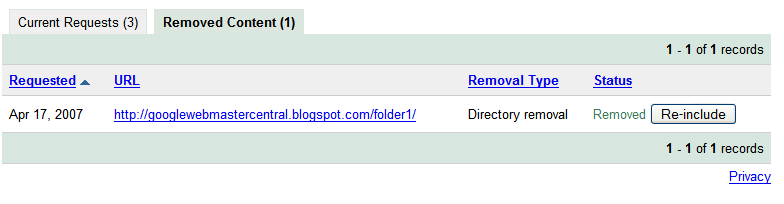
Checking the status of removal requests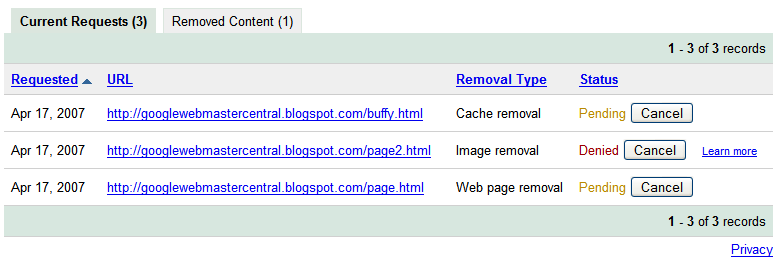
 Requesting removal of content you don't own
Requesting removal of content you don't own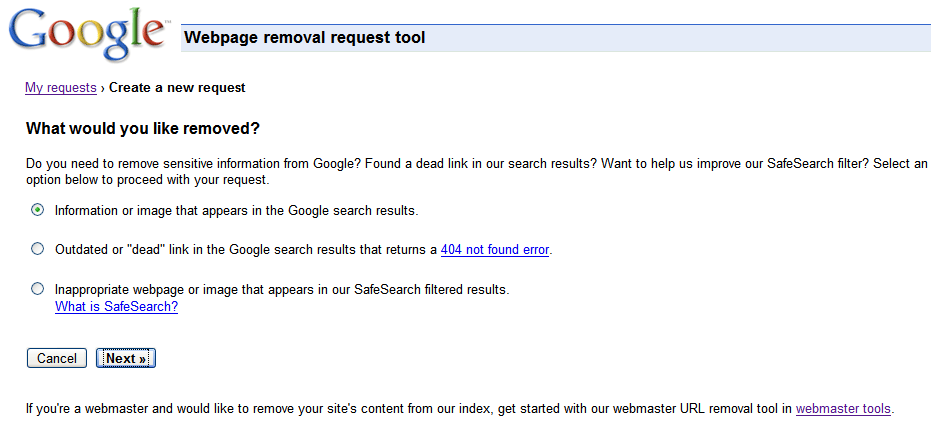 Since Google indexes the web and doesn't control the content on web pages, we generally can't remove results from our index unless the webmaster has blocked or modified the content or removed the page. If you would like content removed, you can work with the site owner to do so, and then use this tool to expedite the removal from our search results.
Since Google indexes the web and doesn't control the content on web pages, we generally can't remove results from our index unless the webmaster has blocked or modified the content or removed the page. If you would like content removed, you can work with the site owner to do so, and then use this tool to expedite the removal from our search results.
 You can check on the status of pending requests, and as with the version available in webmaster tools, the status will change to Removed or Denied once it's been processed. Generally, the request is denied if it doesn't meet the eligibility criteria. For requests that involve personal information, you won't see the status available here, but will instead receive an email with more information about next steps.
You can check on the status of pending requests, and as with the version available in webmaster tools, the status will change to Removed or Denied once it's been processed. Generally, the request is denied if it doesn't meet the eligibility criteria. For requests that involve personal information, you won't see the status available here, but will instead receive an email with more information about next steps.