salam every one, this is a topic from google web master centrale blog: The Googlebot activity reports in webmaster tools show you the number of pages of your site Googlebot has crawled over the last 90 days. We've seen some of you asking why this number might be higher than the total number of pages on your sites.
Googlebot crawls pages of your site based on a number of things including:
pages it already knows about
links from other web pages (within your site and on other sites)
pages listed in your Sitemap file
More specifically, Googlebot doesn't access pages, it accesses URLs. And the same page can often be accessed via several URLs. Consider the home page of a site that can be accessed from the following four URLs:
http://www.example.com/
http://www.example.com/index.html
http://example.com
http://example.com/index.html
Although all URLs lead to the same page, all four URLs may be used in links to the page. When Googlebot follows these links, a count of four is added to the activity report.
Many other scenarios can lead to multiple URLs for the same page. For instance, a page may have several named anchors, such as:
http://www.example.com/mypage.html#heading1
http://www.example.com/mypage.html#heading2
http://www.example.com/mypage.html#heading3
And dynamically generated pages often can be reached by multiple URLs, such as:
As you can see, when you consider that each page on your site might have multiple URLs that lead to it, the number of URLs that Googlebot crawls can be considerably higher than the number of total pages for your site.
Of course, you (and we) only want one version of the URL to be returned in the search results. Not to worry -- this is exactly what happens. Our algorithms selects a version to include, and you can provide input on this selection process.
Redirect to the preferred version of the URL You can do this using 301 (permanent) redirect. In the first example that shows four URLs that point to a site's home page, you may want to redirect index.html to www.example.com/. And you may want to redirect example.com to www.example.com so that any URLs that begin with one version are redirected to the other version. Note that you can do this latter redirect with the Preferred Domain feature in webmaster tools. (If you also use a 301 redirect, make sure that this redirect matches what you set for the preferred domain.)
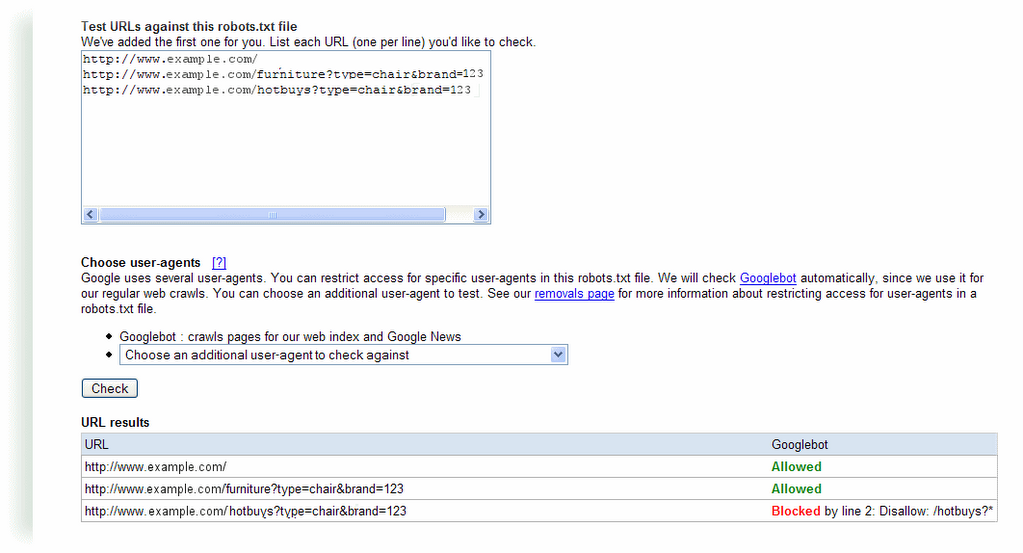
Block the non-preferred versions of a URL with a robots.txt file For dynamically generated pages, you may want to block the non-preferred version using pattern matching in your robots.txt file. (Note that not all search engines support pattern matching, so check the guidelines for each search engine bot you're interested in.) For instance, in the third example that shows two URLs that point to a page about the chairs available from brand 123, the "hotbuys" section rotates periodically and the content is always available from a primary and permanent location. If that case, you may want to index the first version, and block the "hotbuys" version. To do this, add the following to your robots.txt file:
User-agent: Googlebot Disallow: /hotbuys?*
To ensure that this directive will actually block and allow what you intend, use the robots.txt analysis tool in webmaster tools. Just add this directive to the robots.txt section on that page, list the URLs you want to check in the "Test URLs" section and click the Check button. For this example, you'd see a result like this:
Don't worry about links to anchors, because while Googlebot will crawl each link, our algorithms will index the URL without the anchor.
And if you don't provide input such as that described above, our algorithms do a really good job of picking a version to show in the search results.this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com
salam every one, this is a topic from google web master centrale blog: We've gotten a few questions about whether you can put multiple Sitemaps in the same directory. Yes, you can!
You might want to have multiple Sitemap files in a single directory for a number of reasons. For instance, if you have an auction site, you might want to have a daily Sitemap with new auction offers and a weekly Sitemap with less time-sensitive URLs. Or you could generate a new Sitemap every day with new offers, so that the list of Sitemaps grows over time. Either of these solutions works just fine.
Or, here's another sample scenario: Suppose you're a provider that supports multiple web shops, and they share a similar URL structure differentiated by a parameter. For example:
Since they're all in the same directory, it's fine by our rules to put the URLs for all of the stores into a single Sitemap, under http://example.com/ or http://example.com/stores/. However, some webmasters may prefer to have separate Sitemaps for each store, such as:
As long as all URLs listed in the Sitemap are at the same location as the Sitemap or in a sub directory (in the above example http://example.com/stores/ or perhaps http://example.com/stores/catalog) it's fine for multiple Sitemaps to live in the same directory (as many as you want!). The important thing is that Sitemaps not contain URLs from parent directories or completely different directories -- if that happens, we can't be sure that the submitter controls the URL's directory, so we can't trust the metadata.
The above Sitemaps could also be collected into a single Sitemap index file and easily be submitted via Google webmaster tools. For example, you could create http://example.com/stores/sitemap_index.xml as follows:
Then simply add the index file to your account, and you'll be able to see any errors for each of the child Sitemaps.
If each store includes more than 50,000 URLs (the maximum number for a single Sitemap), you would need to have multiple Sitemaps for each store. In that case, you may want to create a Sitemap index file for each store that lists the Sitemaps for that store. For instance:
Since Sitemap index files can't contain other index files, you would need to submit each Sitemap index file to your account separately.
Whether you list all URLs in a single Sitemap or in multiple Sitemaps (in the same directory of different directories) is simply based on what's easiest for you to maintain. We treat the URLs equally for each of these methods of organization.this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com
Seo Master present to you: Nicholas C. Zakas delivers the seventh Web Exponents tech talk at Google. Nicholas is a JavaScript guru and author working at Yahoo!. Most recently we worked together on my next book, Even Faster Web Sites. Nicholas contributed the chapter on Writing Efficient JavaScript, containing much of the sage advice found in this talk. Check out his slides and watch the video.
Nicholas starts by asserting that users have a greater expectation that sites will be fast. Web developers need to do most of the heavy lifting to meet these expectations. Much of the slowness in today's web sites comes from JavaScript. In this talk, Nicholas gives advice in four main areas: scope management, data access, loops, and DOM.
Scope Management: When a symbol is accessed, the JavaScript engine has to walk the scope chain to find that symbol. The scope chain starts with local variables, and ends with global variables. Using more local variables and fewer global variables results in better performance. One way to move in this direction is to store a global as a local variable when it's referenced multiple times within a function. Avoiding with also helps, because that adds more layers to the scope chain. And make sure to use var when declaring local variables, otherwise they'll end up in the global space which means longer access times.
Data Access: In JavaScript, data is accessed four ways: as literals, variables, object properties, and array items. Literals and variables are the fastest to access, although the relative performance can vary across browsers. Similar to global variables, performance can be improved by creating local variables to hold object properties and array items that are referenced multiple times. Also, keep in mind that deeper object property and array item lookup (e.g., obj.name1.name2.name3) is slower.
Loops: Nicholas points out that for-in and for each loops should generally be avoided. Although they provide convenience, they perform poorly. The choices when it comes to loops are for, do-while, and while. All three perform about the same. The key to loops is optimizing what is performed at each iteration in the loop, and the number of iterations, especially paying attention to the previous two performance recommendations. The classic example here is storing an array's length as a local variable, as opposed to querying the array's length property on each iteration through a loop.
DOM: One of the primary areas for optimizing your web application's interaction with the DOM is how you handle HTMLCollection objects: document.images, document.forms, etc., as well as the results of calling getElementsByTagName() and getElementsByClassName(). As noted in the HTML spec, HTMLCollections "are assumed to be live meaning that they are automatically updated when the underlying document is changed." Any idea how long this code takes to execute?
var divs = document.getElementsByTagName("div"); for (var i=0; i < divs.length; i++) { var div = document.createElement("div"); document.body.appendChild(div); }
This code results in an infinite loop! Each time a div is appended to the document, the divs array is updated, incrementing the length so that the termination condition is never reached. It's best to think of HTMLCollections as live queries instead of arrays. Minimizing the number of times you access HTMLCollection properties (hint: copy length to a local variable) is a win. It can also be faster to copy the HTMLCollection into a regular array when the contents are accessed frequently (see the slides for a code sample).
Another area for improving DOM performance is reflow - when the browser computes the page's layout. This happens more frequently than you might think, especially for web applications with heavy use of DHTML. If you have code that makes significant layout changes, consider making the changes within a DocumentFragment or setting the className property to alter styles.
There is hope for a faster web as browsers come equipped with JIT compilers and native code generation. But the legacy of previous, slower browsers will be with us for quite a while longer. So hang in there. With evangelists like Nicholas in the lead, it's still possible to find your way to a fast, efficient web page.
By Steve Souders, Performance Evangelist
Check out other blog posts and videos in the Web Exponents speaker series:


 Don't worry about links to anchors, because while Googlebot will crawl each link, our algorithms will index the URL without the anchor.
Don't worry about links to anchors, because while Googlebot will crawl each link, our algorithms will index the URL without the anchor.