Création des Logiciels de gestion d'Entreprise, Création et référencement des sites web, Réseaux et Maintenance, Conception

Création des Logiciels de gestion d'Entreprise, Création et référencement des sites web, Réseaux et Maintenance, Conception
Today's release of the Dart SDK and Editor is the first beta release, and contains performance and productivity improvements across the platform. This latest release helps Dart developers automate code evolution, produce smaller JavaScript code and deploy Dart web apps.
The Editor's analysis engine, responsible for reporting warnings and errors, is completely rewritten and is 20% faster at parsing and analyzing. Now, there’s no need to run all the unit tests just to discover a typo. The Dart Editor watches your back as you type.
In addition, Dart Editor makes it easier for developers to manage an evolving app. Some of the new features include:
Code completion has also improved. For example, completion is now camelcase aware. Type iE and Dart Editor finds isEmpty.

Compiling Dart to JavaScript now results in smaller code. For example, some Dart programs that use reflection and HTML can compile to JavaScript that is 3.7x smaller than previous compilation sizes.
Dart VM performance has also improved. Compared against the previous release of Dart, DeltaBlue is 33% faster and Tracer is 40% faster. This release also includes full SIMD acceleration in Dart VM.
Finally, deploying a Dart web app is now easier, with the beta pub deploy command. It creates a directory with your app's code and assets and prepares it for hosting on your favorite web server. You can use this command from Dart Editor or the pub command-line utility.
That's just the highlights - there are more improvements across the platform. You can read the full release notes for more details and changes. You can download the latest version of Dart Editor, including everything you need for Dart development, from dartlang.org. We look forward to your feedback!
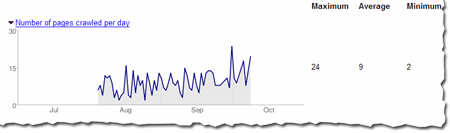

 In general, the load time of a page doesn't affect its ranking, but we wanted to give this info because it can help you spot problems. We hope you will find this data as useful as we do!this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.com
In general, the load time of a page doesn't affect its ranking, but we wanted to give this info because it can help you spot problems. We hope you will find this data as useful as we do!this is a topic published in 2013... to get contents for your blog or your forum, just contact me at: devnasser@gmail.comUser-agent: *Googlebot will crawl everything in the site other than pages in the cgi-bin directory.
Disallow: /
User-agent: Googlebot
Disallow: /cgi-bin/
User-agent: *Googlebot won't crawl any pages of the site.
Disallow: /